Creating sample data viz and dashboards is a common request when we talk about 'the art of the possible'. If we're lucky, we can use the "Sample Sales" data set provided OOTB with OBIEE and OAC. Since the beginning of OBIEE time, Sample Sales has served us well. Fast forward to 2018, we're seeing an increase in demos and proof of concepts with client/customer data, and it's not in excel files anymore.
We're getting data sets which are database extracts, commonly called DUMP files. It's a single file representation of an entire data set within a schema, including tables, fields, permissions and the actual data. Importing dump files into an oracle database can be done via datapump the command line 'impdp'.
Here's how to import a dmp file to an Oracle 12c database. We'll be using command-line sqlplus and an oracle 12c database which are both in a virtual machine running Oracle Linux. This can also be done using the Data Pump Import Wizard using SQL Developer.
Step 1. Know your database directories
I found this to be the most common point of failure when importing data via impdp. Know the dba directories within your oracle db by running. Make sure you're logged in as sysdba:
sqlplus sys as sysdba;
select * from dba_directories;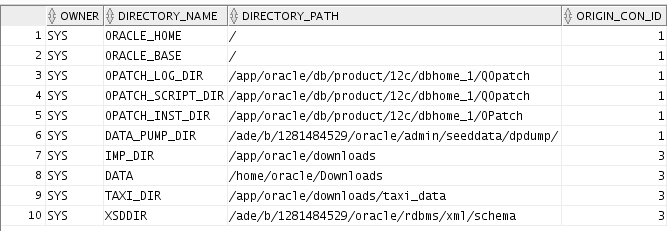
CREATE USER BISAMPLE IDENTIFIED BY Helloworld123;
Creates a schema BISAMPLE with password Helloworld123.
GRANT CONNECT, RESOURCE, DBA TO BISAMPLE;
We are assuming that this user is a power user that can:
Gives BIDEMO user access to dba_directory 'data', in this example its located at /home/oracle/downloads- Allows the user to connect and query the BIDEMO schema (connect)
- Allows the user to create named types for custom schemas (resource)
- Allows the user to not only create custom named types and alter and destroy them as well (DBA)
8. GRANT READ, WRITE ON DIRECTORY DATA TO BIDEMO;
Step 3. Import the dump file
impdp system@orcl full=y directory=DATA dumpfile=BISAMPLE.DMPRunning impdp via command line as outlined above will import the BISAMPLE.dmp file located in /home/oracle/downloads to the schema BISAMPLE.

Take a second to log in as the user we created (BISAMPLE) and verify that the quantity of tables we imported are actually in the schema
sqplus BISAMPLE;
select table_name, status, num_rows from USER_TABLES;
In this import we expect to see 62 tables added to the BISAMPLE schema as verified below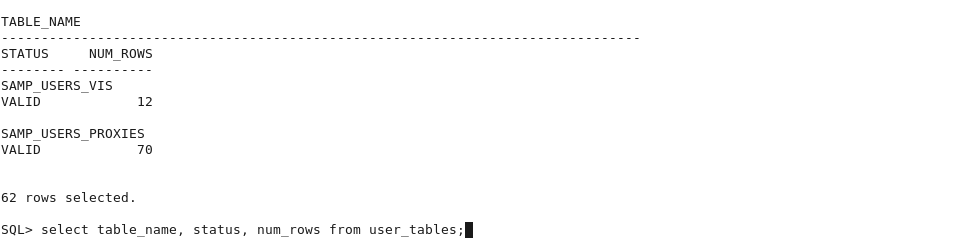
Now we can use the awesome capabilities of Oracle Analytics to connect to this db to perform mash ups, analytics and advanced data viz! I know alot of you guys were asking this as a follow up to our earlier post on creating a shared folder w/in an Oracle Linux Virtual Box. This post should help. Now you can:
- Create or receive a DMP file on your host machine, or via another user
- Transfer the DMP file to the target machine which contains the isolated oracle database
- Use the OBIEE 12c publically available image to create interactive reports, dashboards, data viz, and more!
Happy demoing!